Sentiment Analysis Model
Sentiment_Analysis_Mental_Health
Project Overview
- Builded a ML model to classify mental health status from text data using NLTK and XGBoost.
- Preprocessed the text, did feature engineering and apply TF-IDF as bag of words
- After tunning I saved and tested the model with a 82% accuracy

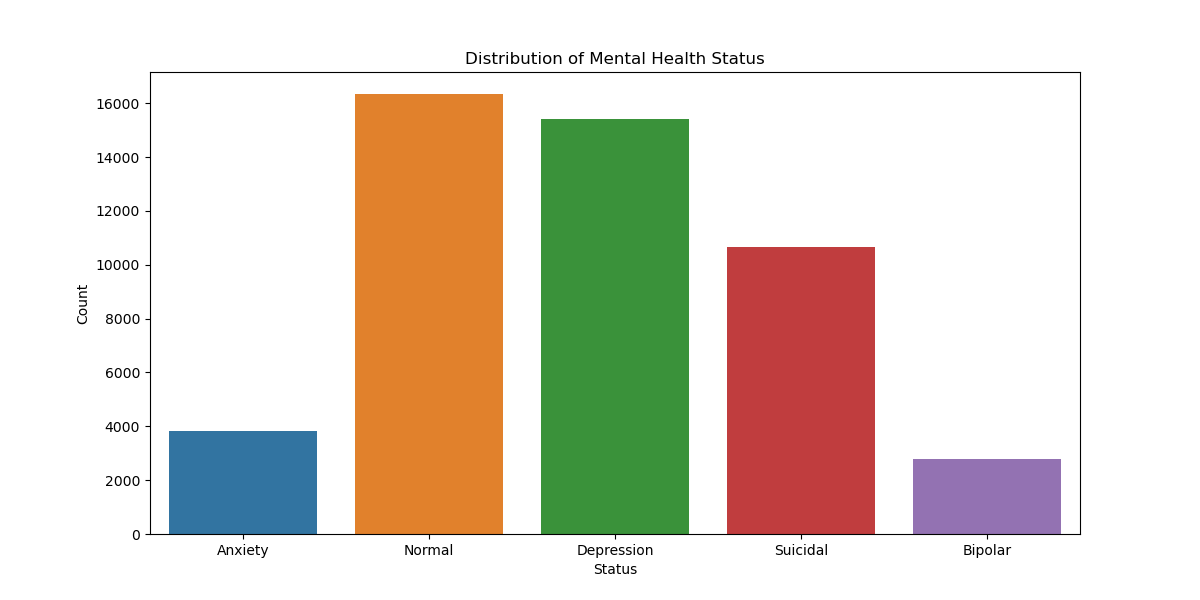
Exploratory Data Analysis
- Understanded and analized the distribution of mental health statuses in the dataset
- Visualized word clouds for different mental health statuses
- Analyzed other important features like text lenghth and average words
See the full code HERE
Data Preprocessing
- Encoded the labels and splited the data into training and test sets
- Resampled the training data to address class imbalance
- Preprocessed the text data by converting to lowercase, removing non-alphanumeric characters, and applying stemming
See the full code HERE
Model Training
- Used TF-IDF vectorization to convert the text data into numerical features
- Performed feature selection using SelectKBest and chi-square
- Trained an XGBoost classifier on the selected features
- Evaluated the model performance using classification report obtaining a 82% accuracy
See the full code HERE
Model Testing
- Loaded the trained XGBoost model, TF-IDF vectorizer, and feature selector
- Implemented a function to predict the mental health status of new text inputs
- Tested the model on sample inputs and printed the predicted labels
See the full code HERE
Conclusions
- We reached a hight accuracy (82%) despite using classical ML and TT-IDF
- We can try a lot of different approaches to improve performance like LSTM, Transformers and embbedings