Roberto_Calzadilla_Projects
My Projects by Roberto Calzadilla
NLP PROJECT - SENTIMENT_CLASSIFICATION
Project overview
- Builded a ML model to classify mental health status from text data using NLTK and XGBoost.
- Preprocessed the text, did feature engineering and apply TF-IDF as bag of words
- After tunning I saved and tested the model with a 82% accuracy
You can access to it HERE

ML PROJECT - RECOMMENDATION SYSTEM
Project overview
- Developed a movie recommendation system using matrix factorization techniques.
- Compared two methods: Regularized Least Squares implemented from scratch versus SVD using the Surprise library.
- The scratch-built model slightly outperformed the library-based model, but with higher complexity and performance.
You can access to it HERE

RAG PROJECT - TRAFFIC REGULATIONS CHATBOT
Project overview
- Developed a chatbot application to help users to clarify questions about Mexico City’s traffic regulations
- Leveraged LangChain, AWS Bedrock, and OpenSearch for the backend infrastructure.
- Implemented the Retrieval-Augmented Generation methodology, using Titan for embeddings and Claude Haiku as the Language Model.
You can access to it HERE

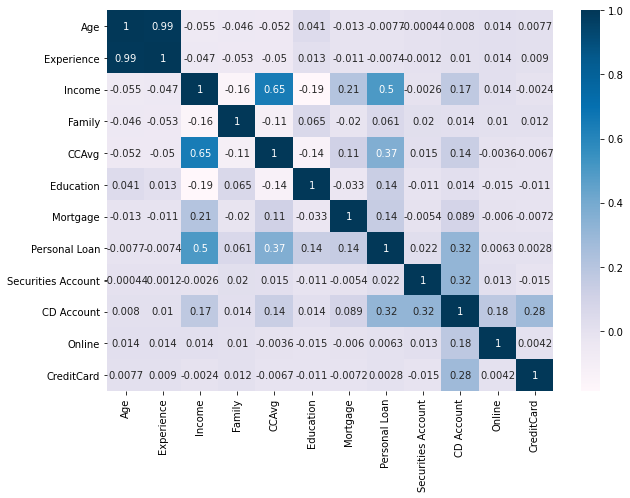
DATA ENGINEERING PROJECT - HOUSE PRICES
Project overview
- Developed a complete ETL process using different technologies (Pyspark, beatifulsoup, AWS, sklearn)
- Scraped information from a real state webpage, the crude data is stored in S3
- Cleaned the data with AWS Glue and pyspark, then loaded it to Athena SQL
- Finally did EDA and model a linear regression to calculate the missing data about total area
You can access to it HERE
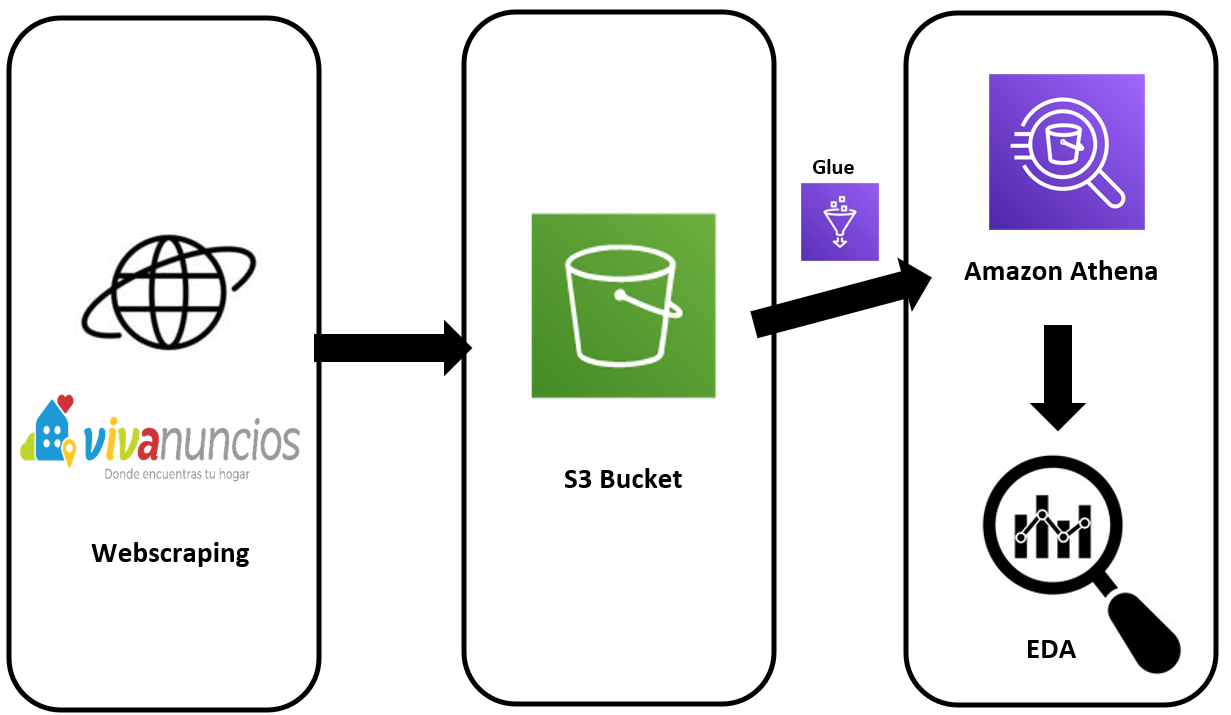
DATA ANALYSIS PROJECT - SALES MANAGEMENT
Project overview
- This projec explores different business metrics and how they can be displayed graphically to follow them
- I explore the relation between sales, budget, costumers and products
- We can obtain conclusions that will help us to make better marketing campaigns and improve profits
- The tools used are SQL server and Power BI
You can access to it HERE
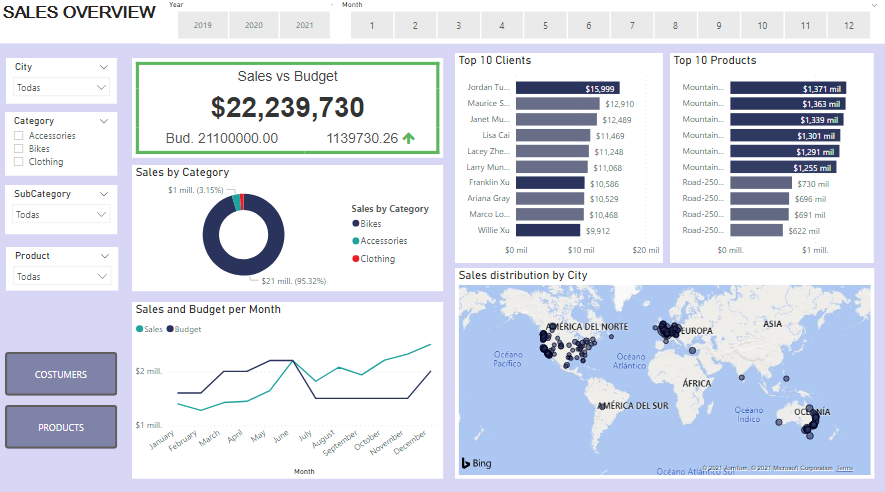
EXCEL DATA ANALYSIS PROJECT
Project overview
- An electronics store needs to increase its profits
- A KPI is found that will allow to increase profits at the lowest cost.
- Sales were evaluated by product, city, time and over time.
- This analysis was done on a database with 180,000 values using Excel only.
You can access to it HERE
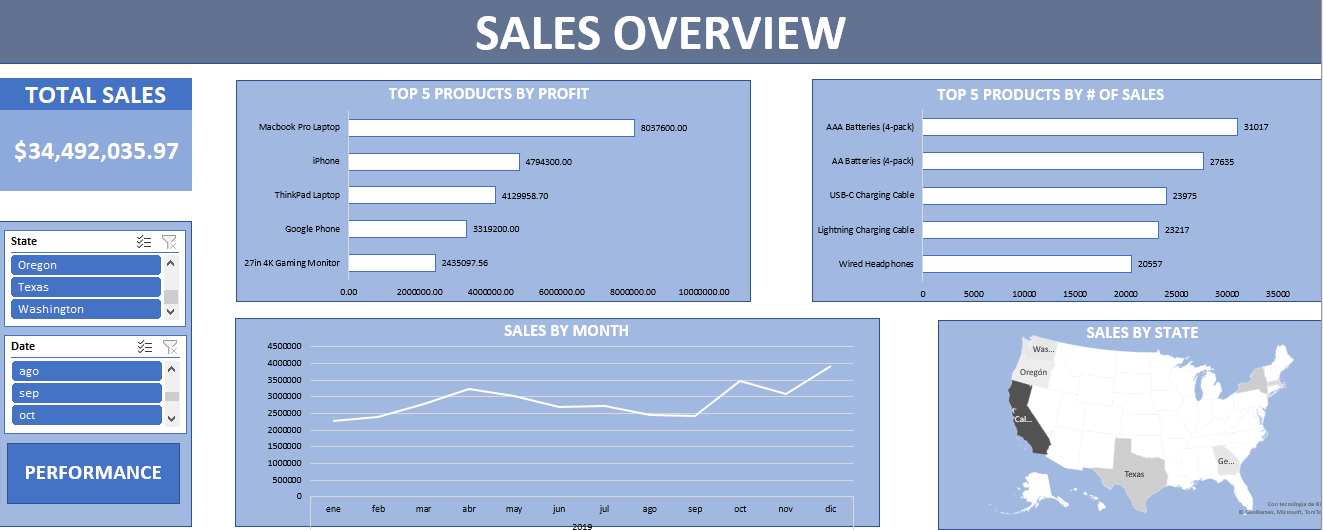
PYTHON - BANK LOANS ANALYSIS
Project overview
- We need to know which factors influence to give a loan
- We also need to look for any opportunity to increase the bank’s assets.
- It was found that apart from income, family size is an important factor to give loans.
- The libraries used were pandas, numpy, matplotlib, seaborn and scipy.
You can access to it HERE